
pythonを用いたデータ解析では、データとなるファイルを読み込んでそのファイルに対する操作を行うことで効果を発揮します。
自分が勝手に指定した変数に自分が決めた値を代入して作ったグラフ等は練習には最適ですが、実際にはデータとなるファイルを用いることになります。
本記事では、ファイル内のデータに対する解析を行うための、ファイルの読み込み方をご紹介いたします。
初心者の方でも、理解できるように丁寧に説明しているので、ぜひ最後までご覧ください。
この記事でわかること
- pandasの基礎知識
- Google Colaboratoryへのファイルの読み込み方
目次
Pandasとは

pandasとは、CSVやExcelなどの表形式のデータを入出力する際に用いる解析ライブラリのことで、基本的に以下のようなことが出来ます。
- データの前処理
- データの結合や部分的な取り出し
- データの集約及びグループ演算
- データに対しての統計処理及び回帰処理
本記事では、主にデータの読み込み方法に触れているので、「データの前処理」や「データの結合や部分的な取り出し」を扱っています。
Pandasのインポート
では、ここからは実際にコードを用いて説明していくので、よろしければ一緒にコードを書いてpandasの使い方を覚えていきましょう。
ちなみに、pythonの始め方に関しては下記の記事に参考にしてください。

では、実際にPandasをインポートして使用していきましょう。
import pandas as pdインポート方法は上記の通りです。
この一文がないとpandasが提供している様々な機能が使えないので必ず先頭に記入しておきましょう。
ファイルの読み込み方法

それでは、pandasを用いてGoogle Colaboratoryにファイルを読み込んでいきましょう。
読み込む手順は以下の通りです。
- オープンデータセットを使ってファイルをパソコンにダウンロード
- ダウンロードしたファイルをGoogle Colaboratoryのフォルダに設置
- pandasを用いて設置したファイルを読み込む
①:オープンデータセットを使ってファイルをパソコンにダウンロード
まず初めに、使用するファイルを探さなければならないため、オープンデータセットからファイルをダウンロードしてきましょう。
ちなみにオープンデータセットとは、公的研究機関や政府が公開しているデータセットのことで、基本的には誰でも無料で閲覧・再配布・二次利用することが出来るといった特徴を持っています。
今回は、オープンデータセットを扱っているKaggleというサイトを使って、読み込みに用いるデータを探そうと思います。
以下のURLでサイトに移ることが出来るので、少し見に行ってみましょう。
Kaggleを見に行きたい方はこちらをタップ!
では、ダウンロードまでの流れを画像を使って説明していきたいと思います。
まず、URLをタップしてもらうと以下の画面に遷移します。

このページが開けたら、画面中央にある「Search datasets」という検索バーをタップしてください。

タップしたら、「search」と書いてある部分に自分が欲しいデータのキーワードを入れます。
その後、FILE TYPESをCSVにしてEnterキーを押し、検索をかけましょう。
ちなみに、私の場合は「Japan」と入力しました。

検索をかけると、そのキーワードに合ったデータセットが表示されると思うので、自分が欲しいデータをタップして表示させましょう。
私は、画面中付近に移っている「Japan Population Data」というデータセットを選びました。
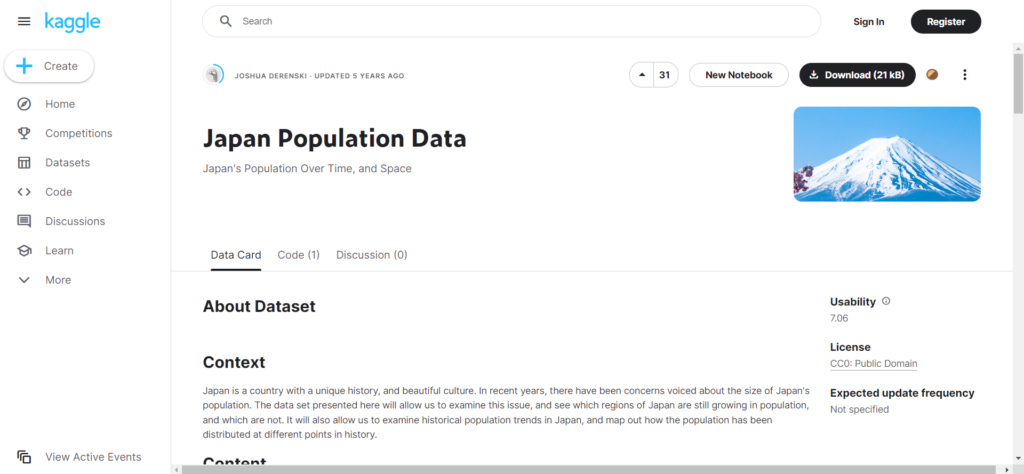
データを選択すると、上記のような画面が表示されます。
ここで各データセットの説明が見れるので、説明文を見ながら自分が使いたいデータセットを探しましょう。
ほしいデータセットが決まったら、右上のダウンロードボタンをクリックします。
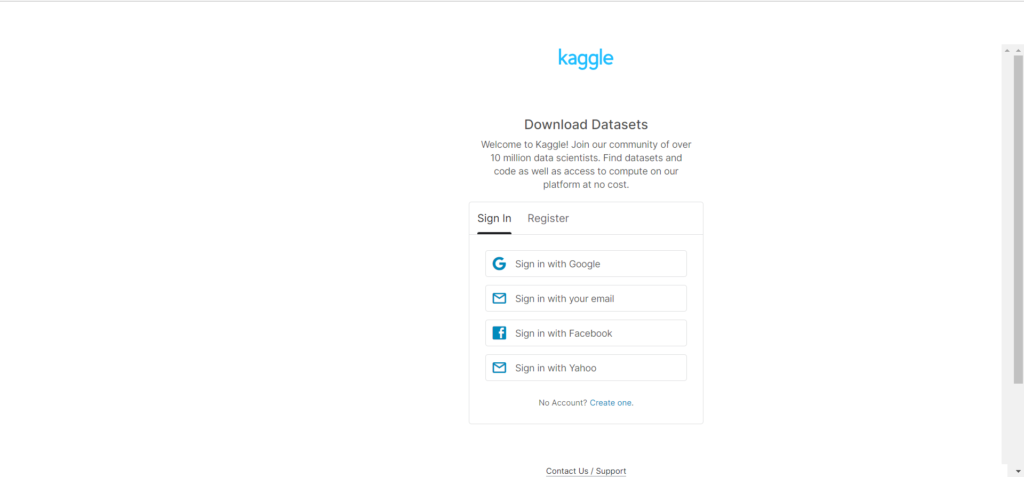
ダウンロードボタンをクリックすると、Kaggleにユーザー登録していない方は上記のような画面が表示されると思うので、Sign inして、データのダウンロードを開始しましょう。
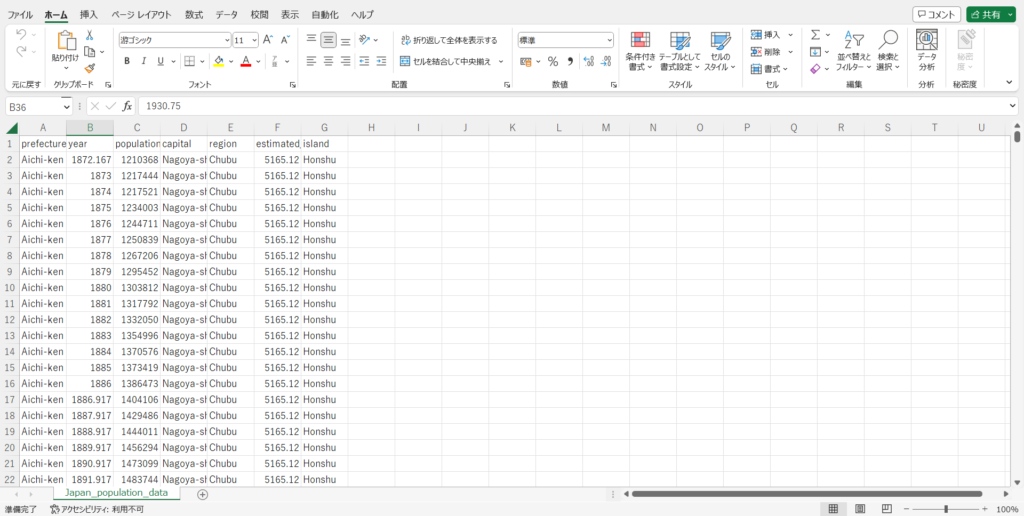
ダウンロードしたファイルを開くと、こんな感じのデータが表示されると思います。
ここまでできれば、ファイルのダウンロードは終了です。
②:ダウンロードしたファイルをGoogle Colaboratoryのフォルダに設置
続いて、先ほどダウンロードしたファイルをGoogle Colaboratoryのフォルダに設置して、Google Colaboratoryからファイルの操作を行えるようにしましょう。
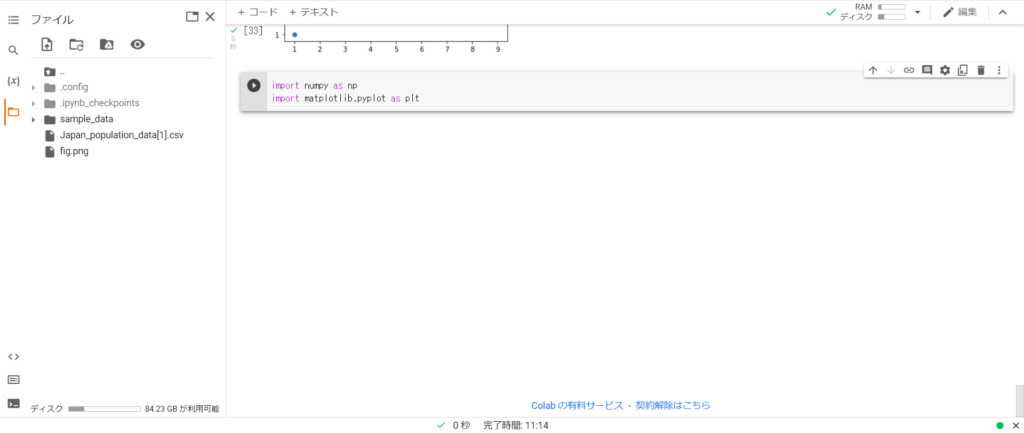
まず初めに、画面左側にあるフォルダアイコンをタップしてファイルウィンドウを開きましょう。
その後、ファイルという文字の下にある4つのアイコンのうち、左から三番目のアイコン「ドライブをマウント」をクリックして、Google Driveをマウントします。
それが終わったら、最後に4つのアイコンのうちの一番左の「アップロードボタン」をクリックして、先ほどダウンロードしたファイルを選択すると、上記の画面のようにcsv形式のファイルが追加されるはずです。
ちなみに、私と同じファイルをダウンロードした場合は、『Japan_population_data[1].csv』という名前のファイルが表示されているはずです。
③:pandasを用いて設置したファイルを読み込む
ここまでで、Google Colaboratoryに無事ファイルを設置することが出来ました。
後は、コードをいじってファイルの内容を読み込んであげましょう。
<input>
import pandas as pd
data = pd.read_csv('Japan_population_data[1].csv')
print(data)<output>
prefecture year population capital region estimated_area \
0 Aichi-ken 1872.1667 1210368.0 Nagoya-shi Chubu 5165.12
1 Aichi-ken 1873.0000 1217444.0 Nagoya-shi Chubu 5165.12
2 Aichi-ken 1874.0000 1217521.0 Nagoya-shi Chubu 5165.12
3 Aichi-ken 1875.0000 1234003.0 Nagoya-shi Chubu 5165.12
4 Aichi-ken 1876.0000 1244711.0 Nagoya-shi Chubu 5165.12
... ... ... ... ... ... ...
2627 Yamanashi-ken 1995.7500 881996.0 Kofu-shi Chubu 4465.37
2628 Yamanashi-ken 2000.7500 888172.0 Kofu-shi Chubu 4465.37
2629 Yamanashi-ken 2005.7500 884515.0 Kofu-shi Chubu 4465.37
2630 Yamanashi-ken 2010.7500 863075.0 Kofu-shi Chubu 4465.37
2631 Yamanashi-ken 2015.7500 835165.0 Kofu-shi Chubu 4465.37
island
0 Honshu
1 Honshu
2 Honshu
3 Honshu
4 Honshu
... ...
2627 Honshu
2628 Honshu
2629 Honshu
2630 Honshu
2631 Honshu
[2632 rows x 7 columns]ファイルの読み込み方法は上記の通りです。
3行目でdataという名前の変数にファイルの内容を代入していることになります。

ファイルの読み込み方法に関しては以上です。ここまでお疲れさまでした。
様々な読み込み方法

ここまでで基本的なデータの読み込み方法に関するお話をしてきました。
しかし、pandasでは単なるデータの読み込みの他にも、解析のためにデータ少し加工して読み込むといったことが可能です。
ここからは、データを加工して読み込む方法をいくつかご紹介していきます。
見出し列の設定・削除
csv形式のファイルには、「見出し行」と呼ばれるものが存在しています。
私のダウンロードしたファイルでいうところの、「prefecture」や「year」にあたるものです。
この見出し行を除いたデータのみを読み込んだり、逆にもともと見出し行がないファイルに対して見出し行を設定追加して読み込んだりすることが出来るのです。
では、実際にコードを見て確認していきましょう。
<input>
import pandas as pd
data1 = pd.read_csv('Japan_population_data[1].csv', header= 1)
data2 = pd.read_csv('Japan_population_data[1].csv', header= None)
data3 = pd.read_csv('Japan_population_data[1].csv', names = ('A', 'B', 'C', 'D', 'E', 'F'))
print('data1の出力結果です。')
print(data1)
print('data2の出力結果です')
print(data2)
print('data3の出力結果です')
print(data3)<output>
data1の出力結果です。
Aichi-ken 1872.1667 1210368 Nagoya-shi Chubu 5165.12 Honshu
0 Aichi-ken 1873.00 1217444.0 Nagoya-shi Chubu 5165.12 Honshu
1 Aichi-ken 1874.00 1217521.0 Nagoya-shi Chubu 5165.12 Honshu
2 Aichi-ken 1875.00 1234003.0 Nagoya-shi Chubu 5165.12 Honshu
3 Aichi-ken 1876.00 1244711.0 Nagoya-shi Chubu 5165.12 Honshu
4 Aichi-ken 1877.00 1250839.0 Nagoya-shi Chubu 5165.12 Honshu
... ... ... ... ... ... ... ...
2626 Yamanashi-ken 1995.75 881996.0 Kofu-shi Chubu 4465.37 Honshu
2627 Yamanashi-ken 2000.75 888172.0 Kofu-shi Chubu 4465.37 Honshu
2628 Yamanashi-ken 2005.75 884515.0 Kofu-shi Chubu 4465.37 Honshu
2629 Yamanashi-ken 2010.75 863075.0 Kofu-shi Chubu 4465.37 Honshu
2630 Yamanashi-ken 2015.75 835165.0 Kofu-shi Chubu 4465.37 Honshu
[2631 rows x 7 columns]
data2の出力結果です
0 1 2 3 4 \
0 prefecture year population capital region
1 Aichi-ken 1872.1667 1210368 Nagoya-shi Chubu
2 Aichi-ken 1873 1217444 Nagoya-shi Chubu
3 Aichi-ken 1874 1217521 Nagoya-shi Chubu
4 Aichi-ken 1875 1234003 Nagoya-shi Chubu
... ... ... ... ... ...
2628 Yamanashi-ken 1995.75 881996 Kofu-shi Chubu
2629 Yamanashi-ken 2000.75 888172 Kofu-shi Chubu
2630 Yamanashi-ken 2005.75 884515 Kofu-shi Chubu
2631 Yamanashi-ken 2010.75 863075 Kofu-shi Chubu
2632 Yamanashi-ken 2015.75 835165 Kofu-shi Chubu
5 6
0 estimated_area island
1 5165.12 Honshu
2 5165.12 Honshu
3 5165.12 Honshu
4 5165.12 Honshu
... ... ...
2628 4465.37 Honshu
2629 4465.37 Honshu
2630 4465.37 Honshu
2631 4465.37 Honshu
2632 4465.37 Honshu
[2633 rows x 7 columns]data3の出力結果です
A B C D E \
prefecture year population capital region estimated_area
Aichi-ken 1872.1667 1210368 Nagoya-shi Chubu 5165.12
Aichi-ken 1873 1217444 Nagoya-shi Chubu 5165.12
Aichi-ken 1874 1217521 Nagoya-shi Chubu 5165.12
Aichi-ken 1875 1234003 Nagoya-shi Chubu 5165.12
... ... ... ... ... ...
Yamanashi-ken 1995.75 881996 Kofu-shi Chubu 4465.37
Yamanashi-ken 2000.75 888172 Kofu-shi Chubu 4465.37
Yamanashi-ken 2005.75 884515 Kofu-shi Chubu 4465.37
Yamanashi-ken 2010.75 863075 Kofu-shi Chubu 4465.37
Yamanashi-ken 2015.75 835165 Kofu-shi Chubu 4465.37
F
prefecture island
Aichi-ken Honshu
Aichi-ken Honshu
Aichi-ken Honshu
Aichi-ken Honshu
... ...
Yamanashi-ken Honshu
Yamanashi-ken Honshu
Yamanashi-ken Honshu
Yamanashi-ken Honshu
Yamanashi-ken Honshu
[2633 rows x 6 columns]今回は、data1、data2、data3の三つの読み込み方法を試しています。
まず、data1、data2ですがpd.read_csv関数の引数に新しく『header』というものが加わっていると思います。
これは、表の先頭がどこから始まっているかを指定する変数で、『header = 1』と設定すると、表の二行目から、『header = 2』と設定すると表の三行目から読み込みを始める形になっています。ちなみに、『header = 0』と書くと表の一行目から読み込むので、何も変わらないというわけです。
さらに、data2では『header = None』と設定されていると思うのですが、headerをNoneにすると見出し行がない表だとみなされて勝手に見出し行をつけてくれます。上記の通り、一列目には『0』、二列目には『1』といった感じです。
また、data3ではheaderではなく『names』というものが使われていますが、こちらは見出し行がない表に対して見出し行の名前を自分で決めることのできる変数となっています。上記の例では『names('A','B','C','D''E','F')』と設定しているので、見出し行の部分にアルファベットが表示されているといった感じです。
列を選択して読み込み
続いて、自分で指定した特定の列だけ読み込んでいこうと思います。
<input>
import pandas as pd
data = pd.read_csv('Japan_population_data[1].csv', usecols=[1,2])
print(data)<output>
year population
0 1872.1667 1210368.0
1 1873.0000 1217444.0
2 1874.0000 1217521.0
3 1875.0000 1234003.0
4 1876.0000 1244711.0
... ... ...
2627 1995.7500 881996.0
2628 2000.7500 888172.0
2629 2005.7500 884515.0
2630 2010.7500 863075.0
2631 2015.7500 835165.0
[2632 rows x 2 columns]usecolsを使用することで、読み込む列を減らすことが出来ました。
usecols[1, 2]と設定したら、2行目と3行目が取り出せますね。
ちなみに1行目を取り出したい場合には、usecols[0]と設定すればよいので気になった方は試してみましょう。
<input>
import pandas as pd
data = pd.read_csv('Japan_population_data[1].csv', usecols=['prefecture', 'region'])
print(data)<output>
prefecture region
0 Aichi-ken Chubu
1 Aichi-ken Chubu
2 Aichi-ken Chubu
3 Aichi-ken Chubu
4 Aichi-ken Chubu
... ... ...
2627 Yamanashi-ken Chubu
2628 Yamanashi-ken Chubu
2629 Yamanashi-ken Chubu
2630 Yamanashi-ken Chubu
2631 Yamanashi-ken Chubu
[2632 rows x 2 columns]また、上記のようにusecolsでは列名での指定も行うことが出来ます。
行を選択して読み込み
<input>
import pandas as pd
data = pd.read_csv('Japan_population_data[1].csv', usecols=[1, 2], nrows=5)
print(data)<output>
year population
0 1872.1667 1210368
1 1873.0000 1217444
2 1874.0000 1217521
3 1875.0000 1234003
4 1876.0000 1244711今後は、行を指定して特定の行のみを読み込む方法です。
こちらは、nrowsを使用します。
nrowsに設定した値分の行を取り出すことになるので、膨大な量のデータを処理するときは、『usecols』と『nrows』をうまく併用して、データの量を制限してから処理を行ったりします。
行をスキップして読み込み
<input>
import pandas as pd
data1 = pd.read_csv('Japan_population_data[1].csv', usecols=[1, 2])
data2 = pd.read_csv('Japan_population_data[1].csv', usecols=[1, 2], skiprows = [2,3])
print(data1)
print(data2)<output>
year population
0 1872.1667 1210368.0
1 1873.0000 1217444.0
2 1874.0000 1217521.0
3 1875.0000 1234003.0
4 1876.0000 1244711.0
... ... ...
2627 1995.7500 881996.0
2628 2000.7500 888172.0
2629 2005.7500 884515.0
2630 2010.7500 863075.0
2631 2015.7500 835165.0
[2632 rows x 2 columns]
year population
0 1872.1667 1210368.0
1 1875.0000 1234003.0
2 1876.0000 1244711.0
3 1877.0000 1250839.0
4 1878.0000 1267206.0
... ... ...
2625 1995.7500 881996.0
2626 2000.7500 888172.0
2627 2005.7500 884515.0
2628 2010.7500 863075.0
2629 2015.7500 835165.0
[2630 rows x 2 columns]『skiprows[x, y]』で、x行とy行のデータをスキップして読み込むことが出来ます。
ちなみに、見出し行が一行目としてカウントされるので注意しましょう。
<input>
import pandas as pd
data1 = pd.read_csv('Japan_population_data[1].csv', usecols=[1, 2], skiprows = 2)
data2 = pd.read_csv('Japan_population_data[1].csv', usecols=[1, 2], skipfooter = 2)
print(data1)
print(data2)<output>
1873 1217444
0 1874.00 1217521.0
1 1875.00 1234003.0
2 1876.00 1244711.0
3 1877.00 1250839.0
4 1878.00 1267206.0
... ... ...
2625 1995.75 881996.0
2626 2000.75 888172.0
2627 2005.75 884515.0
2628 2010.75 863075.0
2629 2015.75 835165.0
[2630 rows x 2 columns]
year population
0 1872.1667 1210368.0
1 1873.0000 1217444.0
2 1874.0000 1217521.0
3 1875.0000 1234003.0
4 1876.0000 1244711.0
... ... ...
2625 1985.7500 832832.0
2626 1990.7500 852966.0
2627 1995.7500 881996.0
2628 2000.7500 888172.0
2629 2005.7500 884515.0
[2630 rows x 2 columns]また、『skiprows = x』で先頭からx行分のデータをスキップ、『skipfooter = x』で最後尾からx行分のデータをスキップできるので、あわせて覚えておきましょう。
まとめ
今回は、pandasを使ったデータの読み込みについて一から詳しく紹介していったのですがいかがだったでしょうか。
冒頭でも少し述べましたが、pythonでのデータ解析を行うためにはデータの読み込みは必要不可欠となってきます。
これから先、pythonを用いたデータ解析を行っていくためにもデータの読み込み方法の基本を個々で押さえておきましょう。