

pythonを使って散布図を描いてみたい!
本記事ではこのような要望にお応えしていきます!
ということで今回は、pythonでグラフや図を作成するためのモジュールmatplotlibを使って、簡単な散布図の作成方法をご紹介していきます。
python初心者という方も安心して見れるようにわかりやすくまとめていますので、ぜひ興味のある方は自分の手も動かしながら最後までご覧ください。
この記事でわかること
- 基本的な散布図の書き方
- 散布図のカスタマイズ方法
- 散布図を用いた応用例
目次
散布図作成の準備

実際にグラフを作成していく前に下準備が必要です。
以下のように今回使用するライブラリをインポートしておきましょう。
import numpy as np
import matplotlib.pyplot as pltここで、numpy・matplotlibって何?という方は、ぜひ下記の記事を参考にしてみてください。
それぞれのライブラリの説明と、使い方を初心者の方でもわかりやすいように紹介しています。
関連記事はこちら!
今回行う下準備はこれのみです。
では、実際に散布図を作成していきましょう。
散布図の作成

基本的な散布図グラフの作成
まず初めに、今回の記事の基盤となる基本的な散布図のグラフを作成していきます。
<input>
import matplotlib.pyplot as plt
import numpy as np
x = np.random.randn(25)
y = np.random.randn(25)
plt.scatter(x, y)
plt.show()<output>
plt.scatterという関数が今回のメイン、散布図を作成する関数になっています。
プロットするxの値とyの値を入力して作成する形です。
<input>
import matplotlib.pyplot as plt
import numpy as np
x1 = np.random.randn(25)
y1 = np.random.randn(25)
x2 = np.random.randn(25)
y2 = np.random.randn(25)
plt.scatter(x1, y1)
plt.scatter(x2, y2)
plt.show()<output>
ちなみに、関数同様xとyとscatter関数を二つずつ書くことで同じ平面に二つの散布図を作成することが出来ます。
二つの散布図は自動で色分けされていますね。
散布図のカスタマイズ
<input>
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
x = np.random.randn(25)
y = np.random.randn(25)
ax1.scatter(x,y, color = "r")
ax2.scatter(x,y, s = 300)
ax3.scatter(x,y, marker = "v")
ax4.scatter(x,y, alpha = 0.5)<output>
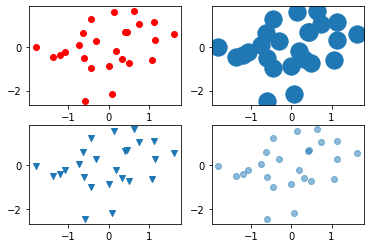
もちろん、散布図の見た目は自分で色々いじれるので、下記の表を参考に皆さんも試してみましょう。
| 引数 | 説明 |
|---|---|
| color | プロットの色を指定する引数です。 上記のコードのように一文字で指定できるものは以下の通りです。 ・b … 青 (Blue) ・g … 緑 (Green) ・r … 赤 (Red) ・c … シアン (Cyan) ・m … マゼンタ (Magenta) ・y … 黄 (Yellow) ・k … 黒 (Black) ・w … 白 (White) 一文字で指定できるものは、8色しか存在していませんが、それ以外にも様々な指定方法があるので興味のある方は調べてみましょう。 |
| s | プロットの大きさを指定する引数です。 |
| marker | プロットの形を指定する引数です。 ・v ・^ ・. ・o などで指定することが出来ます。 |
| alpha | プロットの透明度を指定する引数です。 ・0:完全透明 ・1:不透明 |
| camp | 特徴量に応じた色設定を行うことが出来る引数です。 後ほど個別に説明いたします。 |
続いて、表にもある引数cmapについてです。
<input>
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
x = np.random.randn(25)
y = np.random.randn(25)
colors = np.random.randn(25)
ax1.scatter(x, y, c = colors, cmap = "spring")
ax2.scatter(x, y, c = colors, cmap = "summer")
ax3.scatter(x, y, c = colors, cmap = "autumn")
ax4.scatter(x, y, c = colors, cmap = "winter")
plt.show()<output>
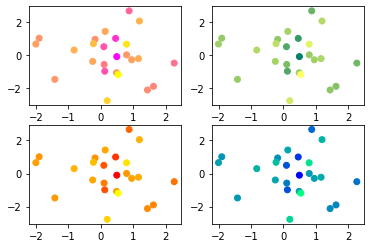
cmapはカラーマップの略で、上記の例では春夏秋冬のカラーマップを利用しています。
一目でどれがどの季節かわかりますか?
やっていることはいたってシンプルで、colorsにランダムな値を入力してこれを特徴量とします。
その後、左上の図であれば春のカラーマップにランダムに生成した特徴量を当てはめて適切な色を出力しているのです。
特徴量をランダムにしておかないと、色がすべて同じになってしまうため、ランダムに生成するようにしているといった感じですね。
散布図の枠線カスタマイズ
<input>
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
x = np.random.randn(25)
y = np.random.randn(25)
ax1.scatter(x, y, color = "white", edgecolor = "red")
ax2.scatter(x, y, color = "white", edgecolor = "green", linewidth = 3)
ax3.scatter(x, y, color = "white",edgecolor = "black", linestyle = "--")
plt.show()<output>
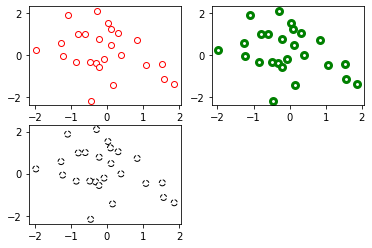
枠線もプロットと同様にカスタマイズすることが出来ます。
下記の表に引数をまとめるので、参考にしてください。
| 引数 | 説明 |
|---|---|
| edgecolor | 枠線の色を指定する引数です。 |
| linewidth | 枠線の太さを指定する引数です。 |
| linestyle | 枠線のスタイルを指定する引数です。 ・- ・-- ・-. ・: で指定することが出来ます。 |
散布図応用例|実際のデータに対して散布図を用いて分析

では、実際に散布図を使ってデータの分析をしてみます。
その前に少しデータ分析のための下準備をしていきましょう。
pandasのインポート・使用するデータ準備
まず、今回の分析に必要なデータとデータ読み込みに必要なpandasというライブラリの用意を行います。
pandasについてよくわからない方は、初心者の方でも理解できるようにpandasの説明を行っているので、以下の記事を参考にしてみてください。
また、以下の記事も今回と同じデータを使っているので、データの取り込み方につきましても、この記事を参考にしてもらえると良いと思います。

では、実際にコードを使ってpandasをインポートしていきましょう。
ちなみに、ファイルの用意に関してはすでに行ってあるものとして話を進めていきます。
import pandas as pd
import matplotlib.pyplot as plt散布図作成のためのmatplotlibも必須となるので、あわせてインポートしておきましょう。
今回使用するデータの説明
今回使用するデータは、Kaggleの『Japan_population_data[1].csv』といったcsv形式のデータセットです。
今回用いるデータセットには7つの特徴量が含まれているので、それぞれの説明を表にまとめておきます。
| 特徴量 | 説明 |
|---|---|
| prefecture | 県名 |
| year | 年 |
| population | 人口 |
| capital | 県庁所在地 |
| region | 地区(関東地方、東北地方等) |
| estimated_area | 推定面積 |
| island | 島(本州、四国等) |
また、参考までに読み込んだデータの出力結果を以下に示しておきます。
<input>
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("Japan_population_data[1].csv")
print(data)<output>
prefecture year population capital region estimated_area \
0 Aichi-ken 1872.1667 1210368.0 Nagoya-shi Chubu 5165.12
1 Aichi-ken 1873.0000 1217444.0 Nagoya-shi Chubu 5165.12
2 Aichi-ken 1874.0000 1217521.0 Nagoya-shi Chubu 5165.12
3 Aichi-ken 1875.0000 1234003.0 Nagoya-shi Chubu 5165.12
4 Aichi-ken 1876.0000 1244711.0 Nagoya-shi Chubu 5165.12
... ... ... ... ... ... ...
2627 Yamanashi-ken 1995.7500 881996.0 Kofu-shi Chubu 4465.37
2628 Yamanashi-ken 2000.7500 888172.0 Kofu-shi Chubu 4465.37
2629 Yamanashi-ken 2005.7500 884515.0 Kofu-shi Chubu 4465.37
2630 Yamanashi-ken 2010.7500 863075.0 Kofu-shi Chubu 4465.37
2631 Yamanashi-ken 2015.7500 835165.0 Kofu-shi Chubu 4465.37
island
0 Honshu
1 Honshu
2 Honshu
3 Honshu
4 Honshu
... ...
2627 Honshu
2628 Honshu
2629 Honshu
2630 Honshu
2631 Honshu 散布図を用いたデータの相関
では、さっそく散布図を用いてデータ解析を行っていきましょう。
今回は、『population:人口』と『year:年』の相関関係を調べていきます。
<input>
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("Japan_population_data[1].csv")
x = data["year"]
y = data["population"]
plt.scatter(x, y)
plt.ylabel("population")
plt.xlabel("year")
plt.show()<output>
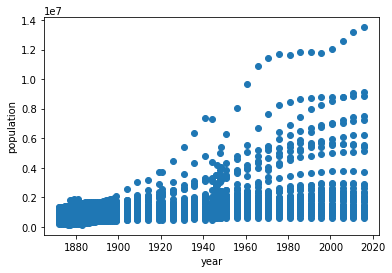
出力結果を確認する前に、まずはコードがどのような操作を行っているかを見ていきましょう。
まず今回は、ファイルのデータを読み込まなければならないので、4行目でdataという変数にファイルのデータを代入しています。
その後、xとyにそれぞれ年と人口のデータを代入して、それを散布図としてプロットしているといった形になっています。
では、次は散布図のほうにスポットを当ててみましょう。
ぱっと見て正の相関関係があることが見て取れるでしょうか?
人口と年の間に正の相関があるということは、年月が経っていくごとに日本の人口が増えていることになりますよね。
これは納得いきます。
しかしこの散布図、綺麗な正の相関になっているでしょうか?
2000年代にもかかわらず、人口がかなり低い位置をとっているプロットがいくつもありますよね。
これはこのデータが、いろいろな県のデータを取ってきたものだからだと考えられます。
なので、この散布図をもっときれいにするために少し工夫をしてあげましょう。
県(prefecture)ごとに分けて考える
先ほどの散布図では、すべての県のデータをまとめて処理してしまったのでうまくいきませんでした。
なので、県ごとに分けて散布図を作ってみましょう。
すべての県に対して散布図を作るのはかなりの労力を必要とするので、今回は四つの県に絞って作成していきます。
<input>
import pandas as pd
import matplotlib.pyplot as plt
plt.figure(figsize=(5,4))
plt.subplots_adjust(wspace=0.4, hspace =0.6)
data = pd.read_csv("Japan_population_data[1].csv")
#愛知県に関する散布図の作成
plt.subplot(2,2,1)
plt.title('Aich')
data_Aichi = data.query('prefecture == "Aichi-ken"')
x_Aichi = data_Aichi["year"]
y_Aichi = data_Aichi["population"]
plt.scatter(x_Aichi, y_Aichi)
#京都府に関する散布図の作成
plt.subplot(2,2,2)
plt.title('Kyoto')
data_Kyoto = data.query('prefecture == "Kyoto-fu"')
x_Kyoto = data_Kyoto["year"]
y_Kyoto = data_Kyoto["population"]
plt.scatter(x_Kyoto, y_Kyoto)
#東京都に関する散布図の作成
plt.subplot(2,2,3)
plt.title('Tokyo')
data_Tokyo = data.query('prefecture == "Tokyo-to"')
x_Tokyo = data_Tokyo["year"]
y_Tokyo = data_Tokyo["population"]
plt.scatter(x_Tokyo, y_Tokyo)
#北海道に関する散布図の作成
plt.subplot(2,2,4)
plt.title('Hokkaido')
data_Hokkaido = data.query('prefecture == "Hokkaido"')
x_Hokkaido = data_Hokkaido["year"]
y_Hokkaido = data_Hokkaido["population"]
plt.scatter(x_Hokkaido, y_Hokkaido)
plt.show()<output>

この図を見ると一目瞭然、どの都道府県も散布図に正の相関があることがわかると思います。
東京都に関しては、ここ150年くらいで人口が10倍近くなっているんですかね。
都道府県ごとの人口の増え幅の違いも見ることが出来て面白いですね。
いくつかあまり見ない関数が出てきたと思いますので、各関数の説明は表にまとめておきますね。
ぜひ参考にしてください。
| 関数 | 説明 |
|---|---|
| plt.figure(figsize=(5,4)) | 出力する画像のサイズを指定しています。 |
| plt.subplots_adjust(wspace=0.4, hspace =0.6) | グラフ間のスペースを指定しています。 wspaceが横のグラフとのスペース、hspaceが縦のグラフとのスペースといった感じです。 |
| data.query('prefecture == "○○"') | queryは、指定の行を取り出す関数になっています。 'prefecture== "○○"と記述すると、prefectureが○○の行をすべて取得といった処理を行います。 |
まとめ
今回は、基本的な散布図の作成方法から実際のデータを用いたデータ解析まで行っていったのですが、散布図に関する理解は深まったでしょうか。
本記事では、日本の人口に関するデータセットを扱ったのですが、他にも様々なデータセットに対して散布図を用いて同じような解析を試すことが出来るので、興味のある方はぜひやってみてください。